
When it comes to OTT live streaming, there are multiple stages at which errors can occur. The delivery chain, multi-bitrate encoders, the origin, and CDN are part of a complex network infrastructure. This means without holistic visibility, issues can arise, and those issues can easily go unnoticed. For OTT broadcasters, that’s where the importance of end-to-end problem management comes in.End-to-end problem management allows broadcasters to detect problems or problem indicators before users are affected. It identifies the origins of these problems and offers long-lasting solutions. Ultimately, end-to-end management prevents disasters by enabling broadcasters to address their underlying causes rather than seeking short-term solutions. It also helps them to put out fires early, ensuring problems don’t have serious consequences for their reputation and revenues.
The problem with outdated problem management

With new big players like Apple TV+, Disney’s upcoming streaming service, and Netflix’s current dominance, streaming feels ubiquitous in 2019. However, many early providers, namely broadcasters that set out to establish market share and test customer uptake, still haven’t updated their initial development monitoring infrastructure. This means two things; wasted time and reputational damage due to completely preventable outages. Imagine an OTT live event, like the Super Bowl, being streamed to millions of viewers. Just at the decisive moment, the live event starts buffering. Today, the wealth of options available to consumers means end-users will simply churn away in unsustainable numbers.
Outdated systems see broadcasters manually piecing together data from disparate elements throughout the delivery chain after a problem has surfaced. This is a time consuming, ineffective way of managing QoS. In fact, outdated problem management can be likened to waiting for your car to break down without simply addressing the engine’s underlying problems.
A key reason why some of these early providers haven’t updated their systems is OTT streaming is growing at a fast pace. Unfortunately, in such a volatile environment, this means the quickest fix is for a broadcaster to pool all resources towards incident management. However, this is a reactive, rather than proactive, approach.
Furthermore, there is a lack of comprehensive problem management tools on the market, with different providers focusing on specific streaming metrics only. Touchstream’s Incident Playback combines data from disparate analytics tools and allows for a greater (and simpler) visibility of the entire OTT streaming infrastructure. This style of tailored end-to-end live stream monitoring allows for more time to be spent fixing root problems, rather than just locating them.
The solution?
Thankfully, as the streaming market grows and streaming providers begin investing more in solutions, the technology in this arena continues to develop rapidly. Touchstream’s Incident Playback system incorporates an easy-to-use comprehensive dashboard that visualizes the entire delivery chain. Crucially, it allows service teams to effectively rewind an incident back-in-time and analyse it in real time. New systems like these mean data and reports previously compiled manually by outdated systems can now be seamlessly delivered to stakeholders as an end-to-end, holistic visualisation.
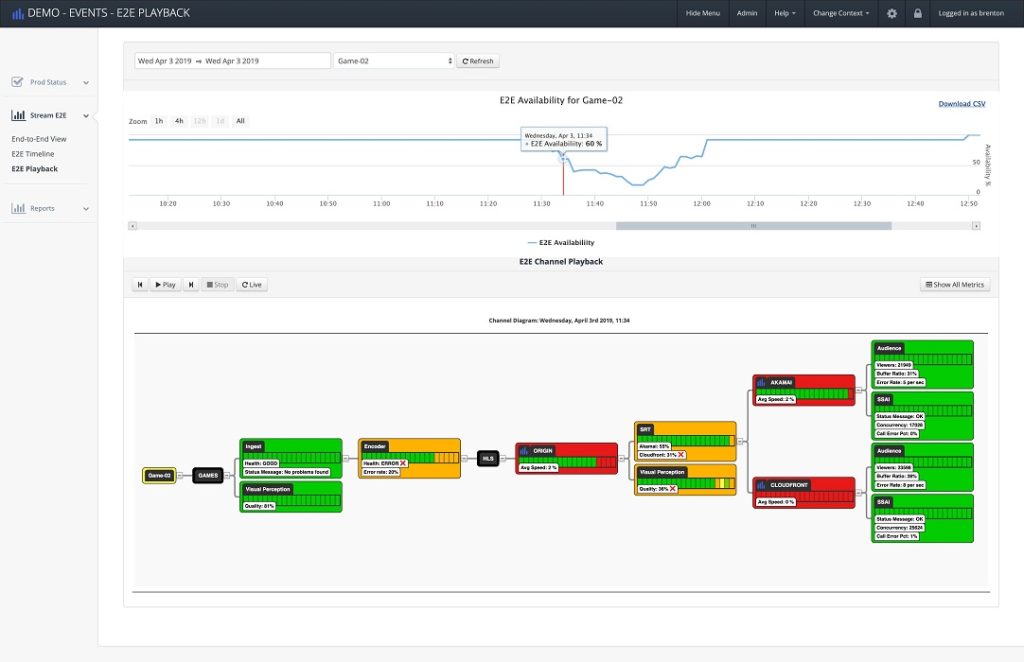
Touchstream’s Incident Playback interface allows service teams to rewind an incident and analyse it as it happened
Problem vs. incident management
Problem and incident management both draw on two key IT service management (ITSM) practices from the ITIL suite of best practices. Touchstream’s Incident Playback service allows for ITIL best practices to be carried out seamlessly. In addition, it makes it easy to visualize and log problems, resulting in a faster diagnosis and a more in-depth analysis that leads to the root of the issue.
These ITIL best practices are comprised of several phases taken on by different service operator teams:
- Problem control, during which service operators find issues in the network and determine their priority, based on its impact on users. Each problem is then allocated to a team.
- Error control sees service operators investigate an existing problem that’s been flagged by problem control, and pass on the resulting information to other teams. Importantly, they define the required steps to resolve the issue moving forward. They also monitor the implementation of these steps.
- Major problem review allows the team to understand the root of a problem. What are the lessons learnt from previous outages and major issues? What can be changed in the process or infrastructure to make sure it doesn’t happen again?
- Proactive problem management is the final, and key, phase in problem management. Implementations and changes discussed in the major problem review are put into effect here.
Therefore, whilst incident management places a focus on the rapid diagnosis of a problem and restoration of the affected network services, providing a quick solution, problem management goes deeper to provide a systematic review of past incidents. Incident management can be likened to papering over the cracks: since a speedy solution is usually demanded, teams end up ignoring the root cause of the issue.
When combined with an ongoing review of trends in network usage, proper problem management allows a broadcaster to adapt their entire infrastructure by permanently removing underlying problems, and preventing future incidents. Although its investigative dimension can be time-consuming, it’s necessary to ensure broadcasters don’t get left behind when it comes to long-term optimisation.
Thus, incident management is, of course, a necessity. Ideally, though, both of these processes (incident management and problem management) will work in tandem. Data from incident management helps problem management to find the cause and prevent future disruptions to services. The end goal should always be to rely more on problem management than incident management; preventing problems instead of picking up the pieces after an outage.
Providing the QoS end-users demand
Today, QoS is paramount to a broadcaster’s success in an ever-more competitive streaming market. Online users are increasingly unforgiving and see broadcast television as a quality benchmark. With high user expectations and a multitude of options for consumers, poor QoS causes unsustainable user abandonment for streaming operators, as can be seen in the graphic below:

The key QoS metrics to monitor (according to Streaming Video Alliance) are Video Start-up Time, Video Start Failure (yes or no), Rebuffering Ratio (%) and Average Media Bit Rate. All of these can be integrated from audience measurement systems into our StreamE2E platform. Incident Playback, our new addition, is an extension of the E2E platform that we are happy to announce as the result of valued customer collaboration. Extensive feedback led us to realise customers most wanted to have the ability to thoroughly analyse past incidents. Thus, our new system has allowed us to minimise previously irritating issues to the point that they are almost inconsequential.
That’s why customers like Sky UK and Telstra, as well as leading Australian broadcasters Seven West Media, are all gaining valuable insights and visibility through Touchstream. Our all-encompassing SaaS solution allows them to continuously provide the high-quality service their users have traditionally associated with their brand in an ever-evolving broadcast and streaming landscape. End-to-end problem management improves long term overall QoS by allowing broadcasters stamp out issues at their root so the end-user remains happy and loyal to their broadcaster.
For a more in-depth take on how our Incident Playback system allows seamless problem management, be sure to read our White Paper about 'Moving From Triage To Post Mortem' here.

